2-3000 db POST-olt változót szeretnék ciklussal lementi mysql-be és/vagy kiküldeni e-mail-ben, azonban a szerver 30 másodperc után timeout-ol (kb. 6-800 változó feldolgozása után).
A szolgáltató nem engedi ennél nagyobbra emelni max execution time-ot és a háttérben sem futtatható a skript, mert előtte kell a humán interakció (rekordok kijelölése :) ).
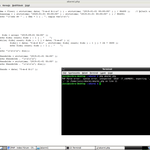
Elkezdtem egy programot írni php-ban. Ha csinálok valamit, szinte minden lépésnél megnézem az eredményt.
Eddig 4 egyszerű sornál tartok és már hiba van benne.
Csináltam egy képernyőmentést, amin jól látható a négysoros szkript, illetve a futtatás eredménye.
Akárhogy is nézem, nem látom a hibát benne.
A kurzorral végigmentem minden soron, mindegyik sor vége -ahogy az a mellékelt képen is látható- az utolsó olvasható karakterrel fejeződik be. Tehát nincs benne semmi plusz karakter elrejtve.
Meglepő módon hibás sornak érzékeli a kommentblokk első sorát. Azt vajon miért?
Ha nincs szukseg cimkefelhore illetve kiirni, hogy adott cimke hany masik cikkhez tartozik, akkor nincs szukseg kulon tablara es kapcsolotablara. Eleg egy text oszlop erre, megfelelo szeparatorral, vagy ha postgreSQL is rendelkezesre all (es szimpatikusabb), akkor az alapbol tamogatja a tomb tipust. Bar bizonyos cikk/cimkemennyiseg (arany) eseten a kulon tabla hatekonyabb lehet.
Azt találd ki, milyen adatbázis-táblával tudnád ezt reprezentálni. Annyit segítek, hogy n:m kapcsolatról van szó: minden cikkhez tartozhat több címke, minden címkéhez tartozhat több cikk.
nem foglalkoztam meg PHP-vel se adatbazis keszitessel.
Most csinalok egy honlapot amihez a kovetkezot szeretnem megvalositani:
Minden egyes aloldalhoz rendelnek egy-egy tag-et vagy keyword-ot , hogy rakattintva vagy a keresobe beirva a hasonlo tag-gel, keyword-del ellatott aloldalak jojjenek fel.
Termeszetesen nem kerek senkit, hogy irja meg helyettem az egeszet, csak adjatok tippet , hogy milyen kulcsszavakkal induljak el a google keresobe.
Sokkal probalkoztam, de mindenhol csak "form" adatok elmentese szerepel, szoval vmi kulcsszo hianyzik.
Ha nem teljesen vilagos, hogy mit szerentek az alabbi link altal jobban el tudom magyarazni. Itt a cikk cime felett van 5 db tag amire rakattitva hasonlo tag-elt cikkek jonnek fel.
Ez már egy fokkal jobb, bár ebben még mindig ott a sok szóköz, és újsor karakter, de attól eltekintve már json-string.
Én azonban arra jöttem rá, hogy ha a json-t dekódolom, akkor az objektum elemeire már tudok ékezetes betűkkel hivatkozni.
Tehát a json1-es példádnál maradva
$objektum = json_decode( $json1 );
echo $objektum->árvíztűrő;
a kimenet: tükörfúrógép
Ez volt a lényeg, hogy tudom-e használni vagy nem, illetve ehhez kell-e bármilyen konverziót, kódolást alkalmazni vagy sem.
Mivel láttam, hogy a kapott string valamilyen (u-szekvenciás) kódolású, eleve meg sem próbálkoztam az ékezetes betűk használatával, csak problémának láttam, amivel nem tudok mit kezdeni.
Meglepődve tapasztaltam, hogy de igen lehet. Viszont a terminálomon (linux) nem kriksz-krakszokat kapok, hanem u-szekvenciákat. A terminálomon megjelenítek ékezetes betűket ugyanúgy, mint kínai "kriksz-krakszokat".
Tényleg nem a php hibája, ha ezeket a szekvenciákat nem találja, nem ismeri fel, hiszen akár ascii-kódú karakterek is lehetnek.
úgymond saját (human readable) formában fog megjeleníteni, ami viszont nem json-kompatibilis.
Ajanlom figyelmedbe az RFC (8259) megfelelo sorait:
...A string begins and ends with quotation marks. All Unicode characters may be placed within the quotation marks, except for the characters that MUST be escaped: quotation mark, reverse solidus, and the control characters (U+0000 through U+001F).
Any character may be escaped. ...
Az, hogy a terminalodon (windows cmd.exe) kriksz-krakszokat latsz, nem a php hibaja.
A $vars egy json string, így a kimeneten (terminál) megjelenik egy jó hosszú string, ahol többek között az é betű helyett \u00e9, az ő helyett pedig \u0151, és a többi ékezetes betű helyett is hasonló kódolású karakterkód-ot látok.
Ezt a $vars stringet fájlba írom, eredmény természetesen ugyanez.
Ha írok egy ilyet az echo helyett:
var_dump( json_decode( $vars ) );
akkor annak a kimenete tök jó lesz ékezetek szempontjából, azonban a json_decode egy adatstruktúrát állít elő, amit a var_dump egy úgymond saját (human readable) formában fog megjeleníteni, ami viszont nem json-kompatibilis.
Amit én szeretnék, hogy az $vars stringben \u0151 helyett ő legyen, \u00e9 helyett pedig é. Nyilván tehetnék bele str_replace-t, ami kicseréli, de hagy ne kelljen már nekem ezzel foglalkoznom, ráadásul nemcsak magyar ékezetes betúk vannak, hanem pl. a fok jele (kis karika felül).
Valamilyen programrészletet próbálj beidézni a probléma szemléltetésére, (csak persze előtte sed 's;\\;\\\\;g') Pl: Program: #!/usr/local/bin/php <?php $in1= "\"\\u00e1rv\\u00edzt\\u0171r\\u0151 t\\u00fck\\u00f6rf\\u00far\\u00f3g\\u00e9p\"";
Az a gond, hogy nem ismeri fel benne ezt a kódolást, egyszerűen ASCII-nak érzékeli, a visszaperjelet nem egy speciális karakter kezdetének gondolja, hanem visszapernek. Érdekes módon a \r\n-t ettől függetlenül új sornak veszi.
Ha ilyen egyszerű lenne, akkor nem kérdeztem volna.
Ha kiíratom a json_decode eredményét, ugyanazt kapom. Csak a var_dump jelenít meg nekem unikód nélküli objektumot.
Var_dump nélkül ugyanúgy teli van unikódokkal a stringem.
Nekem egy unikód nélküli json string kell, de azt meg nem csinál a var_dump. Mi több, a var_dump nem is hagyományos értelemben vett függvény, hanem inkább a régi (Pascal-beli) eljáráshoz hasonlatos.
Úgy látszik, hogy kénytelen vagyok str_replace-el kicserélgetni az unkódolást.